定义
ziplist.c的头部给出了ziplist的定义
|
|
由上面的的定义可以看出,ziplist大概看起来就是下面这样子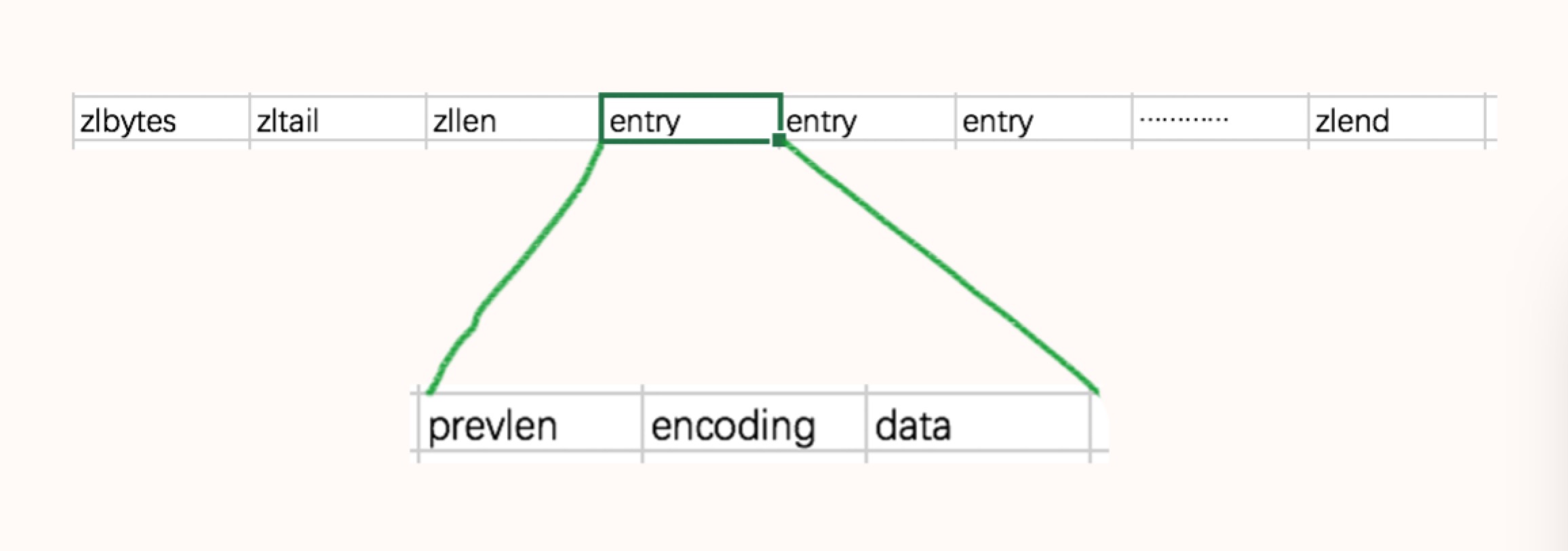
- 其中zllen为4个字节,保存ziplist字节数;
- zltail保存的是尾节点偏移量,4个字节;
- zllen保存的是ziplist的长度,2个字节,ziplist的长度超出范围,只能通过遍历来知道ziplist的长度;
接着是一个个的entry,这是ziplist的节点,entry包含三个字段,第一个是prevlen,记录前一个节点的长度,方便逆向遍历,长度为1个字节或者5个字节,第二个是encoding,里面记录了data段的长度,1个字节到5个字节,最后的一个字段是data段,记录数据;
最后是zlend,结束标志,值为255
源代码分析
|
|
总结
时间问题只写了几个核心函数的注释和一些小函数的注释,不过读懂了那几个函数其它函数其实也就大同小异,先出门喝杯咖啡散散步,什么时候有空补上没有写完的注释。
## 2016/11/22 已经更新完所有注释 ##
能力有限,可能会有错误,欢迎指出,大家一起交流学习。