结构
哈希树的结构如下图所示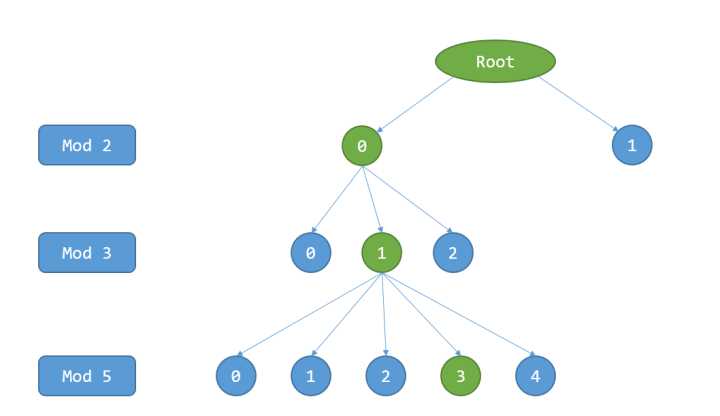
主要思想是:插入的每一个数据通过模多个质数来确定在树中的位置。图为四层哈希树,除第一层外每一层都会有一个质数对即将插入的数取模,质数从最小开始,逐步增大,如图中第二层的质数为2,第三层为3,第四层为5(如果有第五层则为7)。首先假设最下面一层(第四层)才存储数据,其它层(第一道三层)都不存储数据。假如要插入28,则其检索路径就如上图所示。最终它被插入到第四层的绿色节点中。
容量
基于哈希树最下面一层才存储数据的假设,一个4层哈希树的存储容量为
2 * 3 * 5 = 30
容量内不会发生冲突
哈希数据结构最主要的问题是解决键值的冲突。神奇的是,哈希树在容量范围内并不会发生冲突,比如上图的四层哈希树的键值在30以内并不会发生冲突。一个8层的哈希树的容量为:
2 * 3 * 5 * 7 * 11 * 13 * 17 = 510510
且键值在510510内不会发生冲突。
证明如下:
要证明哈希树在容量范围内并不会发生冲突,只需要证明树中存储数据的任意一个节点只对应容量范围内的唯一一个数即可。
设现有一颗n + 1层的哈希树,从第二层到第n+1层的质数分别为m1,m2,m3…mn。现有一个容量范围内的数据x,x除以m1的余数为a1,除以m2的余数为a2,以此类推。即:
x ≡ a1 (mod m1)
x ≡ a2 (mod m2)
x ≡ a3 (mod m3)
…
x ≡ an (mod mn)
令
t1 = k1m1 + a1(k1为非负整数,下面同上)
t2 = k2m2 + a2
…
tn = knmn + an
下面我们试着构造T = t1 + t2 + … + tn,使得T满足:
T ≡ a1 (mod m1)
T ≡ a2 (mod m2)
T ≡ a3 (mod m3)
…
T ≡ an (mod mn)
我们知道,如果t1 % m1 = a1,则(t1 + km1) % m1 = a1,所以若要(t1 + t2) % m1 = a1,则需t2为m1的倍数,以此类推,若要(t1 + t2 + … + tn) % m1 = a1,则当t2,t3…tn都为m1的倍数的时候,等式成立。所以若要:
T % m1 = a1
T % m2 = a2
…
T % mn = an
则:
t1除以m1余a1,t2,t3 … tn都是m1的倍数
t2除以m2余a2,t1,t3 … tn都是m2的倍数
…
tn除以mn余an,t1,t2 … tn - 1都是mn的倍数
整理得:
t1除以m1余a1,t1是m2,m3…mn的公倍数
t2除以m2余a2,t2是m1,m3…mn的公倍数
…
tn除以mn余an,tn是m1,m2…mn - 1的公倍数
置:
t1为满足 除以m1余a1且为(m2m3…mn)的倍数 的数
t2为满足 除以m2余a2且为(m1m3…mn)的倍数 的数
…
tn为满足 除以mn余an且为(m1m2…mn - 1)的倍数 的数
即:
ti = aiMiMi-1
(其中M = m1 + m2 + … + mi, Mi = M / mi, Mi-1为Mi的逆元)
此时T = t1 + t2 + … + tn满足:
T % m1 = a1
T % m2 = a2
…
T % mn = an
但此时的T不是最小解。若a % b = c,则(a - kb) % b = c,所以
x = T - kM(k尽量大,只要x不为负即可)
所以x = T % M,即:
x = (a1M1M1-1 + a2M2M2-1 + … + anMnMn-1) % (m1m2…mn)
所以x是一个小于容量M的唯一的整数解,所以哈希树最后一层的每个位置都可以对应一个容量内的唯一一个整数,所以哈希树在容量内不会发生冲突。
变体
以上所述的哈希树只是在最后一层可以存储数据,容量为:
m1m2…mn
事实上,为了节省空间,第二层到最后一层都可以存储数据,下面这张图很好地说明了这一点:
变体的容量为:
m1 + m1m2 + m1m2m3 + … + m1m2…mn
与哈希表比较
哈希树与哈希表的能实现的功能基本一样,但与哈希表不同的是,哈希树算法是稳定算法,查询一个数据的算法复杂度是O(k),而哈希表查询一个数据正常情况下是O(1)。而且当需要更多的空间存储数据的时候,哈希树只需要增加层数即可,而哈希表需要更多的空间存储数据时则需要rehash并对空间扩容,相对比较麻烦。